Neyman–Pearson lemma
In statistics, the Neyman-Pearson lemma, named after Jerzy Neyman and Egon Pearson, states that when performing a hypothesis test between two point hypotheses H0: θ = θ0 and H1: θ = θ1, then the likelihood-ratio test which rejects H0 in favour of H1 when
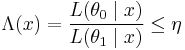
where
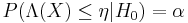
is the most powerful test of size α for a threshold η. If the test is most powerful for all 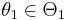 , it is said to be uniformly most powerful (UMP) for alternatives in the set
, it is said to be uniformly most powerful (UMP) for alternatives in the set 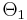 .
.
In practice, the likelihood ratio is often used directly to construct tests — see Likelihood-ratio test. However it can also be used to suggest particular test-statistics that might be of interest or to suggest simplified tests — for this one considers algebraic manipulation of the ratio to see if there are key statistics in it is related to the size of the ratio (i.e. whether a large statistic corresponds to a small ratio or to a large one).
Contents |
Proof
Define the rejection region of the null hypothesis for the NP test as
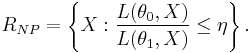
Any other test will have a different rejection region that we define as 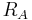 . Furthermore define the function of region, and parameter
. Furthermore define the function of region, and parameter
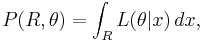
where this is the probability of the data falling in region R, given parameter  .
.
For both tests to have significance level  , it must be true that
, it must be true that
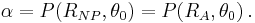
However it is useful to break these down into integrals over distinct regions, given by
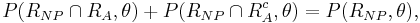
and
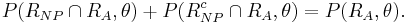
Setting 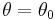 and equating the above two expression, yields that
and equating the above two expression, yields that
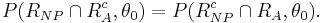
Comparing the powers of the two tests, which are 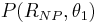 and
and 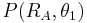 , one can see that
, one can see that
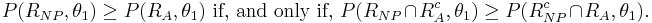
Now by the definition of 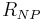 ,
,
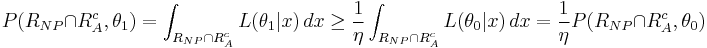
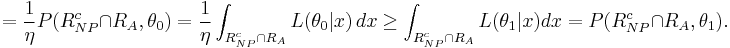
Hence the inequality holds.
Example
Let  be a random sample from the
be a random sample from the 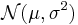 distribution where the mean
distribution where the mean 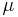 is known, and suppose that we wish to test for
is known, and suppose that we wish to test for 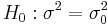 against
against 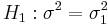 . The likelihood for this set of normally distributed data is
. The likelihood for this set of normally distributed data is
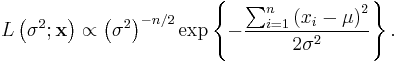
We can compute the likelihood ratio to find the key statistic in this test and its effect on the test's outcome:
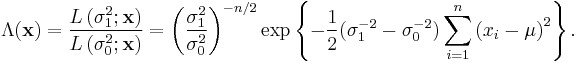
This ratio only depends on the data through 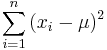 . Therefore, by the Neyman-Pearson lemma, the most powerful test of this type of hypothesis for this data will depend only on . Also, by inspection, we can see that if
. Therefore, by the Neyman-Pearson lemma, the most powerful test of this type of hypothesis for this data will depend only on . Also, by inspection, we can see that if 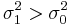 , then
, then 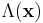 is an increasing function of . So we should reject
is an increasing function of . So we should reject 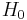 if is sufficiently large. The rejection threshold depends on the size of the test. In this example, the test statistic can be shown to be a scaled Chi-square distributed random variable and an exact critical value can be obtained.
if is sufficiently large. The rejection threshold depends on the size of the test. In this example, the test statistic can be shown to be a scaled Chi-square distributed random variable and an exact critical value can be obtained.
See also
References
- Jerzy Neyman, Egon Pearson (1933). "On the Problem of the Most Efficient Tests of Statistical Hypotheses". Philosophical Transactions of the Royal Society of London. Series A, Containing Papers of a Mathematical or Physical Character 231: 289–337. doi:10.1098/rsta.1933.0009. JSTOR 91247.
- cnx.org: Neyman-Pearson criterion
External links
- Cosma Shalizi, a professor of statistics at Carnegie Mellon University, gives an intuitive derivation of the Neyman-Pearson Lemma using ideas from economics